第 2 章 基础语法
“程序 = 算法 + 数据结构”,数据结构是信息的载体,而算法是完成任务所需要的步骤。两者的构造和使用方法形成了编程语言独特的语法。本章先介绍 R 的基本数据结构,然后介绍条件和循环控制,接着介绍函数的创建与拓展包的使用,最后通过编程实战来实践和掌握本章涉及的知识点。
2.1 基本数据结构
为了表示现实世界的信息,各类编程语言常包含 3 种基本的数据类型:数值型,包括整数和浮点数;字符型,表示文本信息;逻辑型,也常称为布尔值,表示是非判断,如对与错,是与否。在 R 中,除了这些基本数据类型的实现,为了方便计算工作,R 本身还包含了矩阵、数据框和列表等复杂的数据类型,以支持表示各类常用的数据。
2.1.1 向量
在 R 中,数据运算常通过向量的形式进行。向量是一组同质的信息,如 20 个数字、30 个字符串(与数学术语中的向量类似,但不等同)。单一的信息在此被称为元素。标量可以看作元素数量为 1 的向量。
接下来我们通过向量元素的数据类型来实际地了解和操作它。
2.1.1.1 数值
数值应该可以说是最常用的信息表现形式,如人的身高、年龄。在 R 中使用小学学到的阿拉伯表示法即可创建数值,如圆周率 \(\pi\):
此处
#>后显示 R 运行代码后的返回结果,[1]是结果的索引,以辅助用户观测,这里表示结果的第 1 个值是 3.14。
typeof() 与 class() 是两个对于初学者非常有用的函数,它们可以返回数据的类型信息。
在 R 中不需要像其他语言一样区分数值的精度信息,typeof() 返回结果为 double 提示该值是一个浮点数。
在 R 中,任何所见的事物皆为对象,class() 返回对象的类信息,此处是 numeric(数值)。
我们再来看看如何在 R 中表示整数。借助上述两个工具函数,我们不难发现下面的代码与想象不同。
typeof() 与 class() 对于 3 的返回结果与 3.14 完全相同!这是因为即便只输入 3,R 也将其作为浮点数对待。
我们可以利用 identical() 函数或 is.integer() 函数进行检查:
返回的结果是后面将介绍的逻辑值,TRUE 表示对、FALSE 表示错。因此可以判断 3 并不是整数。
正确的整数表示方法需要在数字后加 L 后缀,如 3L。
is.integer() 函数隶属于 is.xxx() 家族,该函数家族用于辅助判断对象是否属于某一类型。读者在 RStudio 中输入 is. 后 RStudio 将智能提示有哪些函数的名字以 is. 开头。
浮点数和整数都是数值,所以下面的代码都会返回 TRUE:
现实中的数据常成组出现,例如,一组学生的身高。R 使用 c() 函数(c 为 combine 的缩写)对数据进行组合:
这样我们就有了一组身高数据。
利用 R 自带的 mean() 和 sd() 还是我们可以轻易求取这组数据的均值和标准差:
# 均值
mean(c(1.70, 1.72, 1.80, 1.66, 1.65, 1.88))
#> [1] 1.735
# 标准差
sd(c(1.70, 1.72, 1.80, 1.66, 1.65, 1.88))
#> [1] 0.08894上面我们计算时我们重复输入了身高数据,如果在输入时发生了小小的意外,如计算标准差时将 1.65 写成了 1.66,那么我们分析得就不是同一组数据了!虽然说在上述的简单计算不太可能发生这种情况,但如果存在 100 甚至 1000 个数据的重复输入,依靠人眼判断几乎是必然出错的。
一个解决办法是依赖系统自带的复制粘贴机制,但如果一组数据被上百次重复使用,这种办法也不实际。
正确的解决办法是引入一个符号(Symbol),用该符号指代一组数据,然后每次需要使用该数据时,使用符号代替即可。符号在编程语言中也常被称为变量,后面我们统一使用该术语。
上述代码块改写为:
heights <- c(1.70, 1.72, 1.80, 1.66, 1.65, 1.88)
mean(heights)
#> [1] 1.735
sd(heights)
#> [1] 0.08894<- 符号在 R 中称为赋值符号,我们可以将它看作数据的流动方向,这样更方便理解,我们不难猜测到 -> 的写法也是有效的:
但通常以 <- 的写法为主。
另外,= 符号与 <- 有基本相同的含义,但不常用。如果读者有其他编程语言经验,也可以使用它作为常用赋值符号。两者的区别见本章【常见问题与方案】一节。
R 中变量的命名有一些限制,最重要的就是不要以数字开头:
变量命名有 2 点建议:
- 对于一些临时使用的变量,以简单为主,如
i、j、k等。 - 与数据相关的命名,建议与其信息一致,如上面的代码我使用了
heights,不然在没有注释的情况下,代码的阅读者无法快速理解你写的程序。
另外,长变量的命名通常有 2 个推荐的规则:
- 骆驼法
以学生身高数据为例,可以写为 studentHeights,它遵循 aBcDeF 这样的构造方式。
- 蛇形
以下划线作为分隔符,写为 student_heights。
两种写法在 R 中都很常用,读者选择一种即可,重点在于一个 R 脚本中应当保持变量名命名风格的一致。
在了解向量和变量后,我们再来学习下向量的计算方式。
假设我们有两组数据,分别以变量 a 和 b 存储:
我们将其堆叠到一起,如图 2.1:
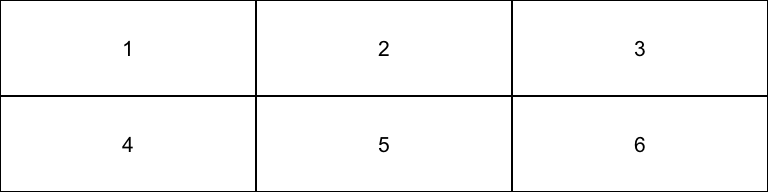
图 2.1: 向量的直观展示
当我们将 a 与 b 相加,结果是什么呢?
两个向量之和是向量元素一一相加组成的向量。如果向量的元素不相同,结果又是如何呢?
我们将 a 与 4 相加看一看,此时向量堆叠如图 2.2 所示:
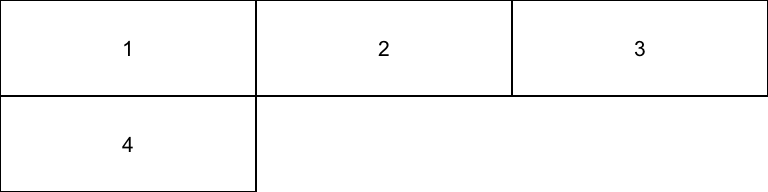
图 2.2: 向量不等长图示
上述结果与 a + c(4, 4, 4) 相同:
因此,如果向量不等长时,短向量会通过重复与长向量先对齐(如图 2.3),然后再相加。
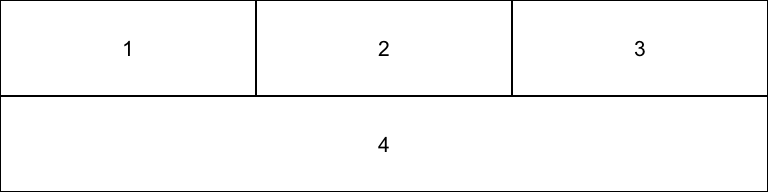
图 2.3: 向量对齐
注意,此过程中,长向量会保持不变,如果出现短向量重复后无法对齐的情况,多余的部分将被扔掉,R 返回结果的同时会抛出一个警告信息。
c(1, 2, 3) + c(4, 5)
#> Warning in c(1, 2, 3) + c(4, 5): 长的对象长度不是短的对
#> 象长度的整倍数
#> [1] 5 7 7
# 上面的加法等价于 c(1, 2, 3) + c(4, 5, 4)整个过程称为向量化运算。除了加法,其他任何向量(几何)运算方式都相同。
# 想减
a - b
#> [1] -3 -3 -3
# 相除
a / b
#> [1] 0.25 0.40 0.50
# 相乘
a * b
#> [1] 4 10 18
# 整除
a %/% b
#> [1] 0 0 0
# 取余数
a %% b
#> [1] 1 2 3
# 平方
a ^ 2
#> [1] 1 4 9
# 取对数
log(a, base = 2)
#> [1] 0.000 1.000 1.585向量化运算的本质是成对的向量元素运算操作。这个特性让 R 在处理数据时非常方便,无论向量元素的个数是多少,在运算时我们都可以将其作为标量对待。
例如,计算数据 heights 的均值和标准差,这里我们直接通过公式而不是 R 自带的函数进行计算:
\[ \mu = \frac{\sum x_i}{n} \]
\[ sd = \sqrt\frac{\sum(x_i - \mu)^2}{n - 1} \]
sd的计算中使用的是n-1而不是n的原因是我们计算的是样本标准差。
实际操作如下:
# 先计算均值
heightsMean <- sum(heights) / length(heights)
heightsMean
#> [1] 1.735
# 计算标准差
heightsSD <- sqrt( sum( (heights - heightsMean)^ 2) / (length(heights) - 1) )
heightsSD
#> [1] 0.08894将结果与 R 函数计算结果对比:
注意,上述我们使用了 R 的一些其他工具函数,length() 用来获取向量的长度,而 sum() 用来获取向量之和,sqrt() 用来计算开方。
初学者可能对于计算中使用的一些计算函数感到陌生,这是非常非常非常正常的,我个人也无法记得所有 R 提供的函数,编程是一门实践课程,读者需要通过使用去熟悉,而无法通过死记硬背掌握。在想要使用自己不知道的函数时,这里有几点建议:
- 猜测函数名。R 的函数命名方式是有规律可循的,且大体有对应的英文含义,读者不妨先尝试猜一猜函数名,看看是否真的有。
- 使用 R 的文档系统。R 的文档系统非常丰富,读者可以在 R 控制台
?numeric来获取关于numeric的相关信息。而??numeric可以进行更为深度的搜索。学会读和理解函数文档是掌握 R 必备的技能。 - 使用搜索引擎。(初学者)遇到的问题基本都会有人遇到,R 的用户众多,各个博客和论坛都记录了关于 R 的使用和问题讨论,在上述 2 点无法解决问题时,读者不妨多使用搜索引擎查找相关资料。
这一小节我们通过数值数据作为对象学习了一些重要的 R 基础概念和操作。接下来我们将这些知识拓展到其他基础数据类型中就相对容易多了。
2.1.1.2 字符串
日常数据处理任务中除了常见的数值型数据,文本数据也比较常用。例如,表示性别是“男”或“女”,教育程度是“中学”还是“大学”。
在 R 中,并不能直接通过输入非数值的字符创建字符串:
文本数据需要通过单引号 '' 或双引号 "" 引号括起来,这样就可以创建字符串了:
单双引号可以通过嵌套以实现单引号或者双引号的输出:
由于 R 的底层实现只有双引号,所以 '"abcde"' 输出中的 " 带有转义符号 \(反斜杠)。读者可以利用转义符号完成对引号(或其他一些特殊符号)的输出操作。
'\'abc' # a 前面的单引号被转义了,''abc' 则是错误的写法
#> [1] "'abc"
"\"\'abc" # 参照上面进行理解,试试运行 ""'abc",你会观察到什么现象?为什么?
#> [1] "\"'abc"函数 nchar() 常用于获取字符串中字符的个数:
注意,这与获取字符串向量的元素个数是不同的:
字符串常涉及集合操作,如交集、并集、差集:
# 交集
intersect(c("a", "b", "c"),
c("a", "b", "d"))
#> [1] "a" "b"
# 并集
union(c("a", "b", "c"),
c("a", "b", "d"))
#> [1] "a" "b" "c" "d"
# 差集
setdiff(c("a", "b", "c"),
c("a", "b", "d"))
#> [1] "c"注意,集合操作同样适用于其他数据类型,读者不妨试一试。
2.1.1.3 因子
因子是另类的字符串,它引入了水平信息,更有利于保存和展示分类的文本数据,创建方式如下:
sex <- factor(c("Male", "Female", "Female", "Male", "Male"))
sex
#> [1] Male Female Female Male Male
#> Levels: Female Male上述结果除了打印向量本身的元素,还输出了变量 sex 的水平信息。水平信息可以通过 levels() 函数获取。
重命名因子水平,可以完成对应所有元素的修改:
水平可以在创建因子时指定,如果一些分类没有对应的水平,将被转换为 NA(Not Available 的缩写),NA 是 R 中比较特殊的一个值,表示数据未知的状态。
factor(c("Male", "Female", "Female", "Male", "Male", "M", "M"), levels = c("Male", "Female"))
#> [1] Male Female Female Male Male <NA> <NA>
#> Levels: Male Female除了水平,我们还可以为分类添加标签以展示某一分类对应的具体信息:
factor(c("Male", "Female", "Female", "Male", "Male", "M", "M"),
levels = c("Male", "Female"),
labels = c("性别:男", "性别:女"))
#> [1] 性别:男 性别:女 性别:女 性别:男 性别:男
#> [6] <NA> <NA>
#> Levels: 性别:男 性别:女初学者需要额外注意,R 代码不支持中文,中文以及特殊字符只能出现在字符串中,两者的换用是代码出错的常见原因。
2.1.1.4 逻辑值
逻辑值仅有 2 个:TRUE 和 FALSE,对应缩写为 T 和 F。一般并不会直接使用逻辑值存储信息,而是使用它管理程序的逻辑,这一点在本章【控制结构与循环】一节中介绍。
逻辑值的另外一个重要作用是对数据取子集,相比于整数索引,它更加的高效。
我们先看一下如何利用整数索引提取子集,如提取变量 heights 的第 2 个元素:
再提取第 2 到第 5 个元素,这会形成新的向量:
这里 2:5 是一个便捷操作,它生成了整数向量 c(2, 3, 4, 5):
如果使用负号,将会去掉对应的元素:
在实际工作中,需要提取的数据子集通常不会这么有序,因此需要借助比较运算符和 which() 函数获取子集数据的索引。
例如,找出身高大于 1.7 的数据:
# 先使用 which() 找出索引
which(heights > 1.7)
#> [1] 2 3 6
# 然后组合取子集操作提取子集数据
heights[which(heights > 1.7)]
#> [1] 1.72 1.80 1.88实际上,我们完全没有必要引入 which() 函数用来返回数据的整数索引,heights > 1.7 比较的结果是一个逻辑值向量,它本身就可以作为索引用于提取子集。
TRUE 对应的元素被保留,而 FALSE 对应的元素被去除。请读者记住,逻辑索引是首选的取子集方式,它更加高效。
2.1.1.5 深入向量
向量除了保存数据,还可以保存与之相关的属性。例如,为了更好展示 heights 信息,我们可以增加名字属性。
names(heights) <- paste("Student:", 1:6)
heights
#> Student: 1 Student: 2 Student: 3 Student: 4 Student: 5
#> 1.70 1.72 1.80 1.66 1.65
#> Student: 6
#> 1.88上述代码中,paste() 将两个向量粘贴到一起,默认中间存在空格。
paste("Student:", 1:6)
#> [1] "Student: 1" "Student: 2" "Student: 3" "Student: 4"
#> [5] "Student: 5" "Student: 6"
# 修改分隔符
paste("Student", 1:6, sep = "-")
#> [1] "Student-1" "Student-2" "Student-3" "Student-4"
#> [5] "Student-5" "Student-6"names() 函数不仅可以设定名字属性,还可以查看:
names(heights)
#> [1] "Student: 1" "Student: 2" "Student: 3" "Student: 4"
#> [5] "Student: 5" "Student: 6"R 中很多函数都与 names() 类似,不仅可以用于修改,同时还可以用于获取对应的信息。
另外,R 对象所具有的属性可以通过 attributes() 函数查看:
attributes(heights)
#> $names
#> [1] "Student: 1" "Student: 2" "Student: 3" "Student: 4"
#> [5] "Student: 5" "Student: 6"R 默认的类系统非常自由,我们可以任意设定属性,如增加一个班级属性:
attr(heights, "class-name") <- "A"
attr(heights, "class-name")
#> [1] "A"
attributes(heights)
#> $names
#> [1] "Student: 1" "Student: 2" "Student: 3" "Student: 4"
#> [5] "Student: 5" "Student: 6"
#>
#> $`class-name`
#> [1] "A"在创建向量时,一些函数会相当有用,如 rep(),它可以用来重复数据。
读者如果想要更新部分向量值,直接对提取的子集重新赋值即可。
2.1.2 数组与矩阵
我们前面看的的向量都是一个维度的,如果我们增加维度信息,将形成数组。2 维的数组比较常用,被称为矩阵。
创建一个 2x2x3 的数组:
array(1:12, dim = c(2, 2, 3))
#> , , 1
#>
#> [,1] [,2]
#> [1,] 1 3
#> [2,] 2 4
#>
#> , , 2
#>
#> [,1] [,2]
#> [1,] 5 7
#> [2,] 6 8
#>
#> , , 3
#>
#> [,1] [,2]
#> [1,] 9 11
#> [2,] 10 12创建一个 4x3 的矩阵:
matrix(1:12, nrow = 4, ncol = 3, byrow = TRUE)
#> [,1] [,2] [,3]
#> [1,] 1 2 3
#> [2,] 4 5 6
#> [3,] 7 8 9
#> [4,] 10 11 12矩阵包含 2 个常用的属性,行名 rownames 和列名 colnames:
上述创建矩阵时我们没有设定,所以默认是 NULL(空值)。我们可以自行设定:
rownames(M) <- paste0("a", 1:4)
colnames(M) <- paste0("b", 1:3)
M
#> b1 b2 b3
#> a1 1 2 3
#> a2 4 5 6
#> a3 7 8 9
#> a4 10 11 12还可以获取矩阵的维度信息:
针对数值矩阵,一些运算非常有用:
# 矩阵和
sum(M)
#> [1] 78
# 矩阵均值
mean(M)
#> [1] 6.5
# 行和
rowSums(M)
#> a1 a2 a3 a4
#> 6 15 24 33
# 列和
colSums(M)
#> b1 b2 b3
#> 22 26 30
# 行均值
rowMeans(M)
#> a1 a2 a3 a4
#> 2 5 8 11
# 列均值
colMeans(M)
#> b1 b2 b3
#> 5.5 6.5 7.5取子集操作依旧是适用的,逗号 , 用于分割不同的维度:
# 第 1 行第 1 列的元素
M[1, 1]
#> [1] 1
# 第 1 行
M[1, ]
#> b1 b2 b3
#> 1 2 3
# 第 1 列
M[, 1]
#> a1 a2 a3 a4
#> 1 4 7 10
# 前 2 行
M[1:2, ]
#> b1 b2 b3
#> a1 1 2 3
#> a2 4 5 6
# 前 2 列
M[, 1:2]
#> b1 b2
#> a1 1 2
#> a2 4 5
#> a3 7 8
#> a4 10 11当取单行时,由于维度信息默认丢失,返回的是一维向量,我们可以显式指定保留矩阵形式,如:
逻辑索引也可以使用:
2.1.3 数据框
数据框(data.frame)是 R 中非常独特的一种数据结构,它可以非常好存储和展示常见的表格数据。从外形上看,它与矩阵非常相似,但与矩阵不同的是,数据框的列可以是不同的数据类型。
例如,创建一个数据框存储性别,年龄和身高数据。
df <- data.frame(
sex = c("F", "M", "M", "F"),
age = c(17, 29, 20, 33),
heights = c(1.66, 1.84, 1.83, 1.56)
)
df
#> sex age heights
#> 1 F 17 1.66
#> 2 M 29 1.84
#> 3 M 20 1.83
#> 4 F 33 1.56str() 非常方便用于观察复杂数据类型的结构:
str(df)
#> 'data.frame': 4 obs. of 3 variables:
#> $ sex : chr "F" "M" "M" "F"
#> $ age : num 17 29 20 33
#> $ heights: num 1.66 1.84 1.83 1.56默认,数据框中字符列会被自动转换为因子类型,我们可以通过设定修改它。
df <- data.frame(
sex = c("F", "M", "M", "F"),
age = c(17, 29, 20, 33),
heights = c(1.66, 1.84, 1.83, 1.56),
stringsAsFactors = FALSE
)
df
#> sex age heights
#> 1 F 17 1.66
#> 2 M 29 1.84
#> 3 M 20 1.83
#> 4 F 33 1.56
str(df)
#> 'data.frame': 4 obs. of 3 variables:
#> $ sex : chr "F" "M" "M" "F"
#> $ age : num 17 29 20 33
#> $ heights: num 1.66 1.84 1.83 1.56很多适用于矩阵的操作同样适用于数据框。
例如,获取维度信息:
例如,获取和设定行、列名:
rownames(df)
#> [1] "1" "2" "3" "4"
colnames(df)
#> [1] "sex" "age" "heights"
rownames(df) <- paste0("Stu", 1:4)
# 将列名大写
colnames(df) <- toupper(colnames(df))
df
#> SEX AGE HEIGHTS
#> Stu1 F 17 1.66
#> Stu2 M 29 1.84
#> Stu3 M 20 1.83
#> Stu4 F 33 1.56数据框支持多种取子集的操作,包括整数索引、逻辑索引、行列名。
先看整数索引:
再看逻辑索引:
df[c(TRUE, TRUE, FALSE, FALSE), c(TRUE, TRUE, FALSE)]
#> SEX AGE
#> Stu1 F 17
#> Stu2 M 29
# 等价于
df[rownames(df) %in% c("Stu1", "Stu2"), colnames(df) %in% c("SEX", "AGE")]
#> SEX AGE
#> Stu1 F 17
#> Stu2 M 29这里 %in% 运算符是成员判断操作,如 'a' %in% c('a', 'b') 是判断 'a' 是否在字符串向量 c('a', 'b') 中。第二种写法看起来比较繁琐,但实际工作中比较常用。
我们还可以直接使用名字:
单独提取某一列生成一个向量是一个常用操作,读者可以使用两种操作符,包括 [[]] 和 $。
例如提取 SEX 列:
需要注意 [[]] 与 [] 的区别,后者依旧返回一个数据框:
另外,取子集操作可以使用 R 提供的 subset() 函数:
# 取行
subset(df, subset = rownames(df) %in% c("Stu1", "Stu2"))
#> SEX AGE HEIGHTS
#> Stu1 F 17 1.66
#> Stu2 M 29 1.84
# 取列
subset(df, select = colnames(df) == "SEX")
#> SEX
#> Stu1 F
#> Stu2 M
#> Stu3 M
#> Stu4 F
# 同时筛选行和列
subset(df, subset = rownames(df) %in% c("Stu1", "Stu2"),
select = colnames(df) == "SEX")
#> SEX
#> Stu1 F
#> Stu2 M数据框如果想要修改或更新某列,像向量一样重新赋值即可:
2.1.4 列表
列表可以表示非常非常非常复杂的数据结构。数据框可以看作列表所有列元素长度相同的特例。
创建一个列表如下:
l <- list(
sex = c("F", "M"),
age = c(17, 29, 20),
heights = c(1.66, 1.84, 1.83, 1.56)
)
l
#> $sex
#> [1] "F" "M"
#>
#> $age
#> [1] 17 29 20
#>
#> $heights
#> [1] 1.66 1.84 1.83 1.56从输出上我们就可以知道如何提取不同的信息:
列表只有 names 属性,没有行列名属性:
类似于数据框,[[]] 取子集得到一个列表元素,而 [] 得到一个子列表。
列表是支持嵌套的,下面我们将两个列表 l 放到一起:
2.2 控制结构
在处理数据分析任务时,我们很少能够简单依赖命令的顺序执行就完成任务。为了处理程序的复杂逻辑以及减少代码量,我们需要学习条件与循环控制的使用。
2.2.1 条件控制
2.2.1.1 if 语句
if 语句是最常用的条件结构,它由 if 关键字、条件判断语句和代码块组成:
条件判断语句结果必须返回一个逻辑值,即 TRUE 或 FALSE。如果返回为 TRUE,随后以 {} 包裹的代码块会被执行。如果我们要处理为 FALSE 的情况,增加一个可选的 else 语句块。
age <- 16
if (age > 18) {
# 为 TRUE 时执行
message("你是个成年人啦!")
} else {
# 为 FALSE 时执行
message("你还是个小孩子哟!")
}
#> 你还是个小孩子哟!代码块中可以包含任意代码,所以 if-else 语句是支持内部嵌套的,结构如下:
如果需要处理的情况是多种,if-else 语句可以连用。例如:
2.2.1.2 switch 语句
swtich 语句在 R 中存在,但读者会极少见到和使用它。结构如下:
这里 EXPR 指代表达式,而 ... 说明可以输入任意参数。
这里只举一个简单的例子:
switch 与函数式编程结合更具不凡的威力,其他场景下我极少见到该语句被使用。因此,我建议初学者了解即可,不必掌握。当然,读者如果遇到非常适合的场景也不妨试一试它,应该是可以让代码更为精炼有效的。
2.2.1.3 提示信息
编写程序时,通过输出一些提示信息可以更好地显示程序的运行状态是否如我们所预期,这是一个初学者需要掌握的一个技巧,能有效避免错误和帮助调试错误。
R 可以通过 print()、message()、cat()、warning() 和 stop() 输出提示信息,只有 stop() 会让程序终止。
读者通过下面的输出比较前几者的差别:
print("Running...")
#> [1] "Running..."
message("Running...")
#> Running...
cat("Running...\n")
#> Running...
warning("Running...")
#> Warning: Running...cat() 与 message() 看起来差别不大,但 cat() 无法被禁止输出,默认没有换行。另外 message() 和 warning() 的信息是可以被抑制掉的,如下:
message("Running...")
#> Running...
suppressMessages(message("Running..."))
warning("Running...")
#> Warning: Running...
suppressWarnings(warning("Running..."))我们再来了解下 stop(),它会直接让程序终止掉,这可以有效避免正确的代码跑错误的数据。
例如,计算均值需要一个数值型数据,但我们却传递了一个字符串:
heights_str <- as.character(heights)
if (!is.numeric(heights_str)) {
stop("无法对字符串计算!")
} else {
# 下面的代码不会被运行
mu <- mean(heights_str)
}
#> Error in eval(expr, envir, enclos): 无法对字符串计算!一般情况下,我推荐读者按需使用 message()/print()、warning() 和 stop() 这几个函数,它们体现信息的 3 个不同级别:
message()/print()提供普通的输出信息。warning()提供需要注意的警告信息。stop()提供令程序停止运行的信息。
2.2.2 循环控制
当我们需要重复某一个(堆)操作时,就需要用到循环的力量了。R 中的循环语句效率历来被人诟病,但实际上已经大有改进。循环语句相比后面提到的 apply 家族函数具有更高的可读性,且容易理解和调试,因此我个人推荐初学者使用。如果本小节提到的几个循环控制语句确实影响到读者程序的效率,再找其他办法也不迟。
在此强调一下,无论是程序的编写还是科研分析工作,完成永远比高效重要。
2.2.2.1 for 语句
for 语句需要配合迭代变量、in 关键字一起使用,结构如下:
这里 i 指代迭代变量,它可以是索引,也可以是子数据集。obj 指代一个可迭代对象。
针对循环打印变量 heights 的信息,可以有以下 2 种方式:
# 第一种方式
# 直接循环迭代对象本身
for (i in heights) {
print(i)
}
#> [1] 1.7
#> [1] 1.72
#> [1] 1.8
#> [1] 1.66
#> [1] 1.65
#> [1] 1.88
# 第二种方式
# 通过索引进行迭代
for (i in 1:length(heights)) {
print(heights[i])
}
#> Student: 1
#> 1.7
#> Student: 2
#> 1.72
#> Student: 3
#> 1.8
#> Student: 4
#> 1.66
#> Student: 5
#> 1.65
#> Student: 6
#> 1.88第二种方式写法看起来更为复杂,但如果针对一些复杂的程序,它则显得更加逻辑分明。
初学者容易犯的一个错误是将 in 后面的可迭代对象写成一个标量,如下:
需要注意下面两者的区别:
一种更好的写法是使用 seq_along(heights) 替代 1:length(heights):
for (i in seq_along(heights)) {
print(heights[i])
}
#> Student: 1
#> 1.7
#> Student: 2
#> 1.72
#> Student: 3
#> 1.8
#> Student: 4
#> 1.66
#> Student: 5
#> 1.65
#> Student: 6
#> 1.88seq_along() 会自动返回可迭代对象的索引序列:
2.2.2.2 while 语句
for 语句已经能满足一般场景的使用,while 语句则特别适合于算法的设计中:
- 不知道要运行多少次循环。
- 知道要退出循环的条件。
下面举一个简单的例子:
2.2.2.3 repeat 语句与循环退出
repeat 语句我从来没有使用过,它类似与 C 语言中的 do-while 语句,即先运行一段程序,然后看一看是否需要退出去。
它的结构如下:
EXPR 指代一个语句块。为了退出 repeat 循环,我们需要借助 break 语句的力量。
下面是一个简单例子:
i <- 1
repeat{
print(i)
i <- i*2
if (i > 100) break
}
#> [1] 1
#> [1] 2
#> [1] 4
#> [1] 8
#> [1] 16
#> [1] 32
#> [1] 64break 语句执行后将跳出当前的循环,另有 next 语句,它可以跳过后续代码的运行进入下一次循环。
基于上面的例子我们再构造一个示例:
i <- 1
repeat{
print(i)
i <- i*2
if (i > 200) break()
if (i > 100) next()
print("Can you see me?")
}
#> [1] 1
#> [1] "Can you see me?"
#> [1] 2
#> [1] "Can you see me?"
#> [1] 4
#> [1] "Can you see me?"
#> [1] 8
#> [1] "Can you see me?"
#> [1] 16
#> [1] "Can you see me?"
#> [1] 32
#> [1] "Can you see me?"
#> [1] 64
#> [1] 128当 i > 100 后,最后一条输出语句就不再运行。
2.3 函数与函数式编程
函数是代码模板。
前面我们使用符号(Symbol)来对数据抽象形成我们所谓的变量,变量名解释了所指向数据的内含但遮掩了底层的结构。类似地,我们也利用符号来对代码块所运行的操作集合进行抽象,并将其称为函数。
- 变量 <- 数据。
- 函数 <- 操作。
这样,函数就使得一组操作可以像使用变量那样重复使用了。
2.3.1 创建和使用函数
我们通过自定义一个计算均值的函数来查看函数是如何创建的:
customMean <- function(x) { # x 是输入参数
# 以下是操作集合,即代码块
s <- i <- 0
for (j in x) {
s <- s + j
i <- i + 1
}
return(s / i) # s / i 是返回值
}一个函数包含输入参数、代码块和返回值 3 部分。当函数中没有使用 return() 时,函数默认会返回最后一个表达式的结果,因此上述代码中将 return(s / i) 改为 s / i 是完全一样的,但后者代码逻辑没有前者清楚。
接下来我们看如何使用这个函数。在创建函数时其实我们已经默认假设输入的是一个数值向量,先试试看:
结果是对的。
假设我们不仅仅想返回结果,还想要打印计算信息,实现如下新的函数版本:
customMean_v2 <- function(x) {
s <- i <- 0
for (j in x) {
s <- s + j
i <- i + 1
}
mu <- s / i
message(
"Mean of sequence ",
paste(x, collapse = ","),
" is ",
mu
)
return(mu)
}再来看下结果:
这样结果看起来更加人性化了。但仔细思考一下,更新后的函数引入了新的问题:如果有 10000 个数字相加,这样打印信息还是一件好事吗?
我们不妨再引入一个新的函数版本,这个版本处理打印以及如何打印的问题:
customMean_v3 <- function(x, verbose = TRUE) {
s <- i <- 0
for (j in x) {
s <- s + j
i <- i + 1
}
mu <- s / i
if (verbose) {
l <- length(x)
if (l > 10) {
message(
"Mean of sequence ",
paste(c(x[1:5], "...", x[(l-4):l]), collapse = ","),
" is ",
mu
)
} else {
message(
"Mean of sequence ",
paste(x, collapse = ","),
" is ",
mu
)
}
}
return(mu)
}我们用这个函数试一下输入少或多的情况。
customMean_v3(x = 1:10)
#> Mean of sequence 1,2,3,4,5,6,7,8,9,10 is 5.5
#> [1] 5.5
customMean_v3(x = 1:100)
#> Mean of sequence 1,2,3,4,5,...,96,97,98,99,100 is 50.5
#> [1] 50.5除此之外,我们在新的版本中引入了一个默认参数 verbose,我们可以选择不打印信息:
当按顺序输入函数参数时,参数的名称是可以不输入的,下面的结果一致:
以上的输入都是基于函数使用者很清楚的知道输入是一个数值型向量,有时候这一点很难做到。例如,你将代码发送给一位不懂编程的人员使用。此时,添加参数检查和注释是有必要的,我们由此创建一个新的函数版本:
# @title 计算均值
# @param x 输入数据,一个数值向量
# @param verbose 逻辑值,控制是否打印
customMean_v4 <- function(x, verbose = TRUE) {
if (!is.numeric(x)) {
stop("输入数据必须是一个数值型向量!")
}
s <- i <- 0
for (j in x) {
s <- s + j
i <- i + 1
}
mu <- s / i
if (verbose) {
l <- length(x)
if (l > 10) {
message(
"Mean of sequence ",
paste(c(x[1:5], "...", x[(l-4):l]), collapse = ","),
" is ",
mu
)
} else {
message(
"Mean of sequence ",
paste(x, collapse = ","),
" is ",
mu
)
}
}
return(mu)
}以# 开始的文本被 R 认为是一个代码注释,后续 @title 和 @param 是注释标签,这些是非必需的,它只是用来更好地描述注释的内容。
代码标签符合 roxygen2 包的定义,有兴趣的读者可以看一看这个包文档。
最后,我们来了解一下函数的计算效率。这里我们将创建的 customMean() 函数与 R 内置的 mean() 函数进行对比。system.time() 函数用来判断函数执行消耗的时间。
system.time(customMean(1:1e7))
#> 用户 系统 流逝
#> 0.280 0.001 0.283
system.time(mean(1:1e7))
#> 用户 系统 流逝
#> 0.047 0.000 0.047elapsed 项给出了计算机执行函数消耗的总时间(以秒为单位),可以看出,内置的函数还是要快很多的。当然,这并不是一个严格的性能测评,但它已经能清楚地表明两者的差距。
2.3.2 作用域
每个函数都有它的领地,更专业地说,当一个函数被创建后,R 中存在一个让这个函数发挥作用的环境。举一个比较形象的例子,冬天我们在购物商场外常常感到寒冷,而进去之后会感到暖和,这是因为商场空调的作用范围只是整个商场。
R 中所有的对象都处于各自的环境之中,我们可以把环境想象成城市里各种不同房子,而对象是处于其中的物品。当然这只是一些形象的比喻,实际上 R 的工作原理可能远不仅如此,但它已经能够很好地帮助理解我们这个概念了。
在启动 R 之后,我们就进去了一个全局环境之中(Global Environment),我们创建的各自变量、函数都会处于其中。这一点我们可以轻易地从 RStudio 右上角的环境窗口中观察到,如图 2.4 所示:
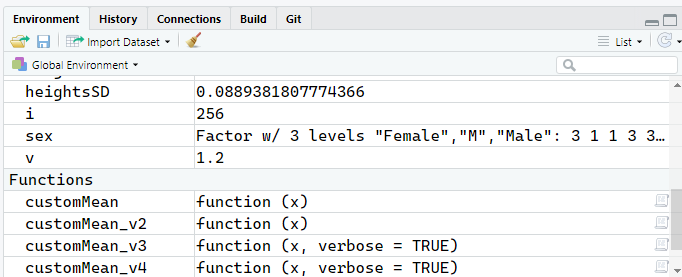
图 2.4: RStudio 的环境窗口
一个函数(如 customMean())与全局环境的关系可以简单用下面两个嵌套的矩形表示:
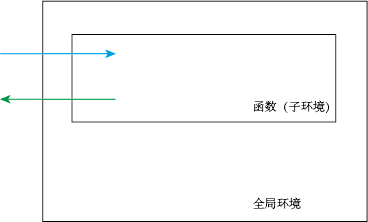
图 2.5: 全局环境与在其中创建的一个函数
我使用了蓝色箭头来表示两者的从属关系,先有全局环境,再有函数环境。我使用绿色箭头表示函数查询变量的方向,先从自己内部查找,如果找不到,再从外部查找。
前面我们创建的函数内部都是自给自足的,下面我们创建一个不一样的。
我在函数 Sum() 之外创建了一个变量 a,而函数内部并没有创建相同名字的变量,这样的函数能够成功调用吗?
我们试试。
结果显示是当然可行的。也就是说,当函数在自身内部无法查询到变量 a 的值时,它会向外面一层寻找。事实上,如果在外层还找不到,而且外层环境如果也处于另一个环境之中,它会再次往外面一层查找。如果按照这个规则真的都找不到,R 就会抛出错误。
如果函数内部存在一个同名变量会怎么样呢?如果读者理解了上面我介绍的规则,那么应该不难猜到下面变量 result 保存的值。
下面揭晓答案:
在某些情景下,我们可能需要在函数内部修改函数外部变量的值。此时我们可以引入新的操作符 <<-,我们简单修改上面的代码看看 全局变量 a 变成了什么。
2.3.3 任意参数
我们在 R 中可能会经常看到函数的参数中有 ... 这样的符号,它代表可以传入任意长度的参数。
例如,我们利用它构造一个可以求取任意个参数之和的函数:
试一试效果:
函数中我们使用了 list() 将传入的 ... 转换为列表,然后再进行处理。除此之外,我们还可以直接使用 ..1、..2 等直接引用 ... 对象中的第 1 个元素、第 2 个元素。
2.3.4 函数式编程
函数不仅仅可以被调用,它还可以被当作函数的参数和返回值,这是函数式编程的特点。
2.3.4.1 传入和返回函数
例如,我们创建一个略显奇怪的函数:
它可以将常见的数值计算函数作为参数计算相应的结果,在讲解之前我们先看看效果:
f(1:10, sum)
#> [1] 55
f(1:10, mean)
#> [1] 5.5
f(1:10, quantile)
#> 0% 25% 50% 75% 100%
#> 1.00 3.25 5.50 7.75 10.00不难理解,上述代码中发挥计算功效的是函数的第 2 个参数。在我们创建的函数 f() 中,我们可以理解为对传入函数的 mean()、sum() 等函数重命名成 fun() 并进行调用。
我们还可以构建一个函数作为返回值的例子:
f() 函数使用了 switch 语句,如果使用 if-else 语句实现该函数也是可以的(读者不妨一试),但此处 switch 让代码更加简明。
下面看看效果:
f2("mean")
#> function (x, ...)
#> UseMethod("mean")
#> <bytecode: 0x7ff794a58e00>
#> <environment: namespace:base>
f2("sum")
#> function (..., na.rm = FALSE) .Primitive("sum")
f2("quantile")
#> function (x, ...)
#> UseMethod("quantile")
#> <bytecode: 0x7ff794b2c9e0>
#> <environment: namespace:stats>返回的全部都是函数,那么我们是不是可以直接调用它呢?
事实证明是可以的。
虽然上面只是通过 2 段简单的代码展示函数式编程的特性,但不难想象到它给 R 语言编程赋予了更多的灵活性。
2.3.4.2 apply 家族
apply 函数家族包括 apply()、lapply()、sapply() 和 vapply() 等成员,其中前三者比较常用。apply 函数家族正是以函数作为输入来进行批量计算,因此它可以取代我们之前学习的循环控制。
2.3.4.2.1 apply
apply() 最常用,针对的也是最常见的表格型数据,在 R 中为矩阵或数据框。
为了展示它的用法和效率,这里我先构造一个 100 列 100,000 行的服从正态分布的数据矩阵:
# 设置随机种子数
set.seed(1234)
mat <- matrix(rnorm(1e7), ncol = 100, byrow = TRUE)
# 展示数据维度
dim(mat)
#> [1] 100000 100
# 查看少量数据
mat[1:5, 1:5]
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] -1.2071 0.27743 1.08444 -2.3457 0.42912
#> [2,] 0.4145 -0.47472 0.06599 -0.5025 -0.82600
#> [3,] 0.4852 0.69677 0.18551 0.7007 0.31168
#> [4,] -0.5800 -0.95328 -0.17943 1.0098 0.02363
#> [5,] -1.2268 0.03615 -0.42139 -0.8994 0.41744现在如果我们想要计算每一行的均值,该怎么实现呢(不使用 rowMeans() 函数)?
先试试使用之前学习的 for 循环构建一个计算函数:
calcRowMeans <- function(mat) {
# 先初始化一个结果向量
# 这样更有效率
res <- vector("numeric", nrow(mat))
for (i in 1:nrow(mat)) {
res[i] <- mean(mat[i, ])
}
return(res)
} 看一下该函数的用时:
10 万行的过程花了不到 1 秒的时间,计算效率着实不低。如果是 apply() 该怎么写呢?效率又如何?
在 apply 写法中,我们没有新建函数,而是直接利用 R 内置的 mean() 函数直接进行计算,相比 for 循环此处的计算效率虽然未见明显提升,但代码却被极度精简了。
让我们来看一下 apply() 是如何完成计算的,其结构如下:
第 1 个参数是数组(可以是矩阵和数据框),第 2 个参数是设置按行(设为 1)或列(设为 2)逐行取子集,第 3 个参数是对子集调用的函数,接下来是传入函数 FUN 中的可选参数列表。前 3 个参数最关键。
因此,在 rm <- apply(mat, 1, mean) 中 apply() 所做的是逐行提取矩阵 mat 的值并传入函数 mean()进行 计算,然后返回结果。
利用 apply() 我们可以抛弃 for 循环对矩阵按行按列各种运算:
# 行和
r <- apply(mat, 1, sum)
# 行最大值
r <- apply(mat, 1, max)
# 行最小值
r <- apply(mat, 1, min)
# 列和
r <- apply(mat, 2, sum)
# 列最大值
r <- apply(mat, 2, max)
# 列最小值
r <- apply(mat, 2, min)上面第 3 个参数传入的函数都是 R 内置的,我们完全可以传入自定义函数,这没有区别。
整体上看,apply() 非常得精简灵活。
2.3.4.2.2 lapply、sapply 和 vapply
lapply()、sapply() 和 vapply() 针对的都是列表结构的数据,sapply() 是简化版本的 lapply(),而 vapply() 则在 sapply() 的基础上加了结果验证,以保证可靠性。
我们假设有 4 组温度数据:
set.seed(1234)
temp <- list(
35 + rnorm(10, mean = 1, sd = 10),
20 + rnorm(5, mean = 1, sd = 3),
25 + rnorm(22, mean = 2, sd = 6),
33 + rnorm(14, mean = 4, sd = 20)
)现在要求取每一组的温度最小、最大、平均值与中位数。我们针对列表的子集创建处理函数:
直接将列表数据、处理函数依次传入 lapply() 函数:
lapply(temp, basic)
#> [[1]]
#> min mean median max
#> 12.54 32.17 30.44 46.84
#>
#> [[2]]
#> min mean median max
#> 18.00 20.26 19.57 23.88
#>
#> [[3]]
#> min mean median max
#> 13.92 24.44 23.96 41.50
#>
#> [[4]]
#> min mean median max
#> 0.8794 22.7069 18.7612 65.9899虽然传入的列表子集不是等长的,但处理的结果却是等长的,因此上述输出看起来略显冗余。
因此我们使用 sapply() 进行简化,它的用法与 lapply() 相同,函数名中的 s 是简化(simplified)的首字母缩写。
sapply(temp, basic)
#> [,1] [,2] [,3] [,4]
#> min 12.54 18.00 13.92 0.8794
#> mean 32.17 20.26 24.44 22.7069
#> median 30.44 19.57 23.96 18.7612
#> max 46.84 23.88 41.50 65.9899是不是更加紧凑?
我们再看一下 vapply():
vapply(temp, basic, numeric(4))
#> [,1] [,2] [,3] [,4]
#> min 12.54 18.00 13.92 0.8794
#> mean 32.17 20.26 24.44 22.7069
#> median 30.44 19.57 23.96 18.7612
#> max 46.84 23.88 41.50 65.9899结果与 sapply() 完全一致。vapply() 第 3 个参数传入对每一个子集调用函数后结果的预期,上述设定为包含 4 个元素的数值型向量。
如果与预期不一致,R 会抛出错误信息:
vapply(temp, basic, numeric(3))
#> Error in vapply(temp, basic, numeric(3)): 值的长度必需为3,
#> 但FUN(X[[1]])结果的长度却是4apply 函数家族还有其他成员,如 tapply(),由于使用频率较低,这里就不再过多介绍。如果有需要,读者也能够基于上述知识轻松地通过 R 提供的代码示例进行快速学习和掌握。
2.4 三方包的安装与加载
R 内置了基础计算、统计分析和绘图包,但依旧无法满足众多 R 用户的个性化需求。目前有超过 10,000 个三方包分布在 CRAN、Bioconductor、GitHub 等平台上,它们得安装方式都不尽相同。
2.4.1 CRAN
CRAN 是由 R 核心团队维护的存档库,大多数的 R 包都发布在 CRAN 上。R 内置了安装命令 install.packages()。
下面是安装著名绘图包 ggplot2 的示例:
本地的源码包也可以通过该命令安装,如安装我本地存有的 sigminer 包:
CRAN 默认使用国外镜像,国内的 R 用户下载包速度可能比较慢,推荐使用 CRAN 清华源。
先使用命令打开配置文件:
然后在该文档内追加内容:
保存后重启 R。
2.4.2 Bioconductor
Bioconductor 是一个生物信息学项目,存储了上千个生物信息学领域相关的软件包、数据包和实验包等。安装 Bioconductor 上的包需要先安装 BiocManager 包:
然后就可以使用 install() 函数安装 Bioconductor 上的包了,如 maftools :
值得一提的是,该命令也可以安装 CRAN 上的包。
读者需要注意 Bioconductor 是有不同的版本的,这可以通过下面命令检查:
尽量保持版本处于最新状态可以获取相关包的最新特性和错误修复。
Bioconductor 默认使用国外镜像,国内的 R 用户下载包速度可能非常慢,推荐使用 Bioconductor 清华源。
先使用命令打开配置文件:
然后在该文档内追加内容:
保存后重启 R。
2.4.3 GitHub 等 Git 库
GitHub 是知名的开源软件库,上面存储了很多 R 包的源代码,包括 CRAN/Bioconductor 包、未发布包以及玩具包。只要有源代码有正确的 R 包框架,就可以通过 remotes 包安装。
例如,安装开发版本的 ggplot2 包:
也有其他对应函数安装其他的 Git 库包,如果 git 库还没有被支持(如中国的 gitee),可以使用 remotes::install_git() 安装。
2.4.4 包使用
R 启动时默认加载的包可以通过 .packages() 命令获取:
print(.packages())
#> [1] "readxl" "data.table" "readr"
#> [4] "dplyr" "ggplot2" "stats"
#> [7] "graphics" "grDevices" "utils"
#> [10] "datasets" "methods" "base"由于在第 1 章的配置一节中我有介绍使用 pacman 包作为第三方的包管理器,在 ~/.Rprofile 中进行了设置,所以该包随着 R 的启动也被加载了。
整个 R 会话当前的所有信息都可以通过 sessionInfo() 获取,在向他人提问时提交该命令结果是一个良好的习惯。
sessionInfo()
#> R version 4.0.0 (2020-04-24)
#> Platform: x86_64-apple-darwin17.0 (64-bit)
#> Running under: macOS Catalina 10.15.4
#>
#> Matrix products: default
#> BLAS: /System/Library/Frameworks/Accelerate.framework/Versions/A/Frameworks/vecLib.framework/Versions/A/libBLAS.dylib
#> LAPACK: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRlapack.dylib
#>
#> locale:
#> [1] zh_CN.UTF-8/zh_CN.UTF-8/zh_CN.UTF-8/C/zh_CN.UTF-8/zh_CN.UTF-8
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets
#> [6] methods base
#>
#> other attached packages:
#> [1] readxl_1.3.1 data.table_1.12.8
#> [3] readr_1.3.1 dplyr_0.8.5
#> [5] ggplot2_3.3.0
#>
#> loaded via a namespace (and not attached):
#> [1] Rcpp_1.0.4.6 cellranger_1.1.0
#> [3] pillar_1.4.4 compiler_4.0.0
#> [5] BiocManager_1.30.10 highr_0.8
#> [7] tools_4.0.0 digest_0.6.25
#> [9] jsonlite_1.6.1 evaluate_0.14
#> [11] lifecycle_0.2.0 tibble_3.0.1
#> [13] gtable_0.3.0 pkgconfig_2.0.3
#> [15] rlang_0.4.6 cli_2.0.2
#> [17] rstudioapi_0.11 yaml_2.2.1
#> [19] xfun_0.14 withr_2.2.0
#> [21] stringr_1.4.0 knitr_1.28
#> [23] vctrs_0.3.0 hms_0.5.3
#> [25] grid_4.0.0 tidyselect_1.1.0
#> [27] glue_1.4.1 R6_2.4.1
#> [29] fansi_0.4.1 rmarkdown_2.1
#> [31] bookdown_0.19 purrr_0.3.4
#> [33] farver_2.0.3 magrittr_1.5
#> [35] scales_1.1.1 ellipsis_0.3.1
#> [37] htmltools_0.4.0 assertthat_0.2.1
#> [39] colorspace_1.4-1 labeling_0.3
#> [41] utf8_1.1.4 stringi_1.4.6
#> [43] munsell_0.5.0 crayon_1.3.42.4.4.1 导入包
当我们需要导入(加载)一个包时,我们可以使用 library() 或 require() 函数。
两个函数的区别在于当 library() 导入一个本地不存在的 R 包时会报错,而 require() 会(隐式)返回为 FALSE,并抛出警告信息。
2.4.4.2 更新包
简单地更新包可以直接通过安装命令进行重装就可以了。
如果是更新所有的包,一个一个安装就未免太麻烦了,如果 R 不提示你,你也不知道有多少包可以更新。
R 默认有函数可以完成这项工作:
但这个函数需要读者不断点击确认,挺麻烦的。
下面推荐几个 3 方包提供的更新命令。
pacman::p_up() # 或 pacman::p_update()
BiocManager::install()
rvcheck::update_all()
remotes::update_packages()其中 rvcheck 是国内大名鼎鼎的 Y 叔 开发的,他有不少文章介绍该包,解决 R 包更新的一些痛点。
2.4.4.3 使用包函数
R 包下载安装后其中函数的使用方法有两种,前面的例子都有涉及到,这里作一个简单介绍。
- 加载后使用
这种方式适合读者需要用到一个包很多的函数,或者有的包需要利用加载过程同时载入它的依赖包,这时也必须加载后才能成功使用。加载后直接调用函数即可,下面是一个 ggplot2 包绘制散点图的例子:
图 2.6: 一个 ggplot2 绘制的简单散点图
- 直接使用
这种方式适合只少量调用 R 包的函数,或者通过这种方式解决不同包存在同名函数问题。
上面我们载入 dplyr 包后,它屏蔽了 base 和 stats 包的一些同名函数。有的同名函数可能功能是一样的,不过做了一些拓展,所以使用起来没有问题。
下面是来自 base 包 union() 函数的示例代码:
(x <- c(sort(sample(1:20, 9)), NA))
#> [1] 1 5 6 7 8 11 12 15 19 NA
(y <- c(sort(sample(3:23, 7)), NA))
#> [1] 6 8 11 12 19 20 21 NA
union(x, y)
#> [1] 1 5 6 7 8 11 12 15 19 NA 20 21但有的函数就不一样了,如 filter() 函数。下面是来自 stats 包 filter() 函数的示例代码:
x <- 1:100
filter(x, rep(1, 3))
#> Error in UseMethod("filter_"): "filter_"没有适用于"c('integer', 'numeric')"目标对象的方法filter() 是一个数据分析过程中经常由于同名屏蔽出现问题的函数(因为 stats 包被 R 默认加载,而 dplyr 又是 R 用户常用的工具包,所以两者经常同时都被加载)。我们可以显式地调用 stats 包里的函数解决该问题:
x <- 1:100
stats::filter(x, rep(1, 3))
#> Time Series:
#> Start = 1
#> End = 100
#> Frequency = 1
#> [1] NA 6 9 12 15 18 21 24 27 30 33 36
#> [13] 39 42 45 48 51 54 57 60 63 66 69 72
#> [25] 75 78 81 84 87 90 93 96 99 102 105 108
#> [37] 111 114 117 120 123 126 129 132 135 138 141 144
#> [49] 147 150 153 156 159 162 165 168 171 174 177 180
#> [61] 183 186 189 192 195 198 201 204 207 210 213 216
#> [73] 219 222 225 228 231 234 237 240 243 246 249 252
#> [85] 255 258 261 264 267 270 273 276 279 282 285 288
#> [97] 291 294 297 NA语法是 包名::函数名。
2.5 编程实战:ROC 曲线计算与绘制
本章的前几节内容涵盖了 R 初学者需要了解和掌握的基础编程知识,包括 R 内置数据结构的创建和使用、R 程序逻辑的控制。 读者在掌握这些内容后已经完全有能力去编写程序完成一些基本事务的处理。为了更好地帮助读者,本节我们通过一个实战项目来整合上述所有的知识点。
本节以数据科学中一个常见的二分类性能评估手段“ROC 曲线”作为目标,编写函数处理连续变量作为预测器时的 ROC 曲线定量和 AUC 计算。
我首先会简单介绍下相应的背景知识,然后呈现整个分析的实现代码,最后对整个过程进行讲解。
我建议读者在了解背景后独立思考如何实现,然后参考我提供的代码动手完成整个实现过程,接着浏览我对代码的讲解,重点深入阅读存疑的部分,反复思考,最后把整个项目从原理到实现完全掌握。
2.5.1 背景与目标
2.5.2 代码实现
2.5.3 代码讲解
2.6 常见问题与方案
除了本节目前罗列的问题,读者在学习本章内容时遇到的其他问题都可以通过 GitHub Issue 提出和进行讨论。如果读者提出的是通性问题,将增补到该节。
2.6.1 复数表示
复数使用频次极少,但它也是一种 R 基础的数据类型。复数的表示方法与其他编程语言类似,使用 i 标定虚部。
例如:
运算符也可以针对复数使用,如:
2.6.2 = 与 <- 的区别
就我个人的使用而言,它的区别在调用函数时比较明显。
例如,计算程序运行时间:
下面的写法是错误的,因为 system.time() 把输入作为参数而不是一个表达式,而该函数并没有 m 这个参数。
system.time(m = customMean(1:1e6))
#> Error in system.time(m = customMean(1:1e+06)): 参数没有用(m = customMean(1:1e+06))例如,调用一个简单的函数时利用 <- 传入参数:
x <- NULL
customMean(x <- 1:100)
#> [1] 50.5
x
#> [1] 1 2 3 4 5 6 7 8 9 10 11 12
#> [13] 13 14 15 16 17 18 19 20 21 22 23 24
#> [25] 25 26 27 28 29 30 31 32 33 34 35 36
#> [37] 37 38 39 40 41 42 43 44 45 46 47 48
#> [49] 49 50 51 52 53 54 55 56 57 58 59 60
#> [61] 61 62 63 64 65 66 67 68 69 70 71 72
#> [73] 73 74 75 76 77 78 79 80 81 82 83 84
#> [85] 85 86 87 88 89 90 91 92 93 94 95 96
#> [97] 97 98 99 100这里先进行了赋值操作,然后才进行函数调用,所以 x 值被更改了。实际对函数传入参数时这种写法是不可取的。
2.6.3 显式使用包函数时 :: 与 ::: 的区别
R 包创建者可以选择哪些函数导出提出给用户使用,哪些是内部计算使用的或是处于开发试验阶段不提供外用。
:: 符号可以获取 R 包导出的函数,也是 R 包加载后可以使用的函数,如 ggplot2 包的 qplot() 函数。
而没有导出的函数则可以通过 ::: 符号获取、调用。
例如 xfun 包的 base_pkgs() 函数。
xfun:::base_pkgs()
#> [1] "base" "compiler" "datasets" "graphics"
#> [5] "grDevices" "grid" "methods" "parallel"
#> [9] "splines" "stats" "stats4" "tcltk"
#> [13] "tools" "utils"下面的方式是错误的:
一般而言,除非你确信你知道这个函数对你有用,且知道如何使用它,否则不建议通过 ::: 调用 R 包的不开放函数。
2.6.4 因子重构
如果我们向变量 sex 扩充两个 M,可能会遇到不能理解的结果:
sex <- factor(c("Male", "Female", "Female", "Male", "Male"))
sex <- c(sex, c("M", "M"))
sex
#> [1] "2" "1" "1" "2" "2" "M" "M"根本原因在于,当我们创建因子后,因子本身存储的实际内容已经被替换为了正整数,分类信息被存储到了水平中,正整数与分类产生的映射对依旧可以保存原本的信息。
sex <- factor(c("Male", "Female", "Female", "Male", "Male"))
str(sex)
#> Factor w/ 2 levels "Female","Male": 2 1 1 2 2这样做的好处是节省内存开销,并有利于模型计算:
- 当存在大量字符串时,R 依然只有少量的正整数即可表示。
- 数学模型并不支持字符串,当将因子纳入统计模型中时,实际上参与计算的是对应的正整数。
解决上述问题的一个办法是先将 sex 转换回字符串,然后再创建因子。
2.6.5 理解 R 计算
- 一切皆是对象。
- 一切皆是函数调用。
John Chambers