tidyverse 中的公式函数
王诗翔 · 2020-12-28
本文的写作由来是知识星球一个朋友对如何在 tidyverse 系列包中使用公式函数(单侧公式)不太熟悉,所以通过本文分享一下我的心得。
构造数据
本文为了聚焦于公式函数本身的用法,我构造的示例数据会非常的简单。
library(tidyverse)
#> ── Attaching packages ─────────────────────────────────────── tidyverse 1.3.0 ──
#> ✓ ggplot2 3.3.2 ✓ purrr 0.3.4
#> ✓ tibble 3.0.4 ✓ dplyr 1.0.2
#> ✓ tidyr 1.1.2 ✓ stringr 1.4.0
#> ✓ readr 1.4.0 ✓ forcats 0.5.0
#> ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
#> x dplyr::filter() masks stats::filter()
#> x dplyr::lag() masks stats::lag()
set.seed(1234)
x <- rnorm(100, mean = 5, sd = 10)
df <- data.frame(
x = x,
y = x + rnorm(100, mean = 0, sd = 1)
)
head(df)
#> x y
#> 1 -7.07 -6.66
#> 2 7.77 7.30
#> 3 15.84 15.91
#> 4 -18.46 -18.96
#> 5 9.29 8.47
#> 6 10.06 10.23我们通过可视化来看下这个数据:
library(ggplot2)
ggplot(df, aes(x, y)) +
geom_point() +
geom_smooth(method = "lm")
#> `geom_smooth()` using formula 'y ~ x'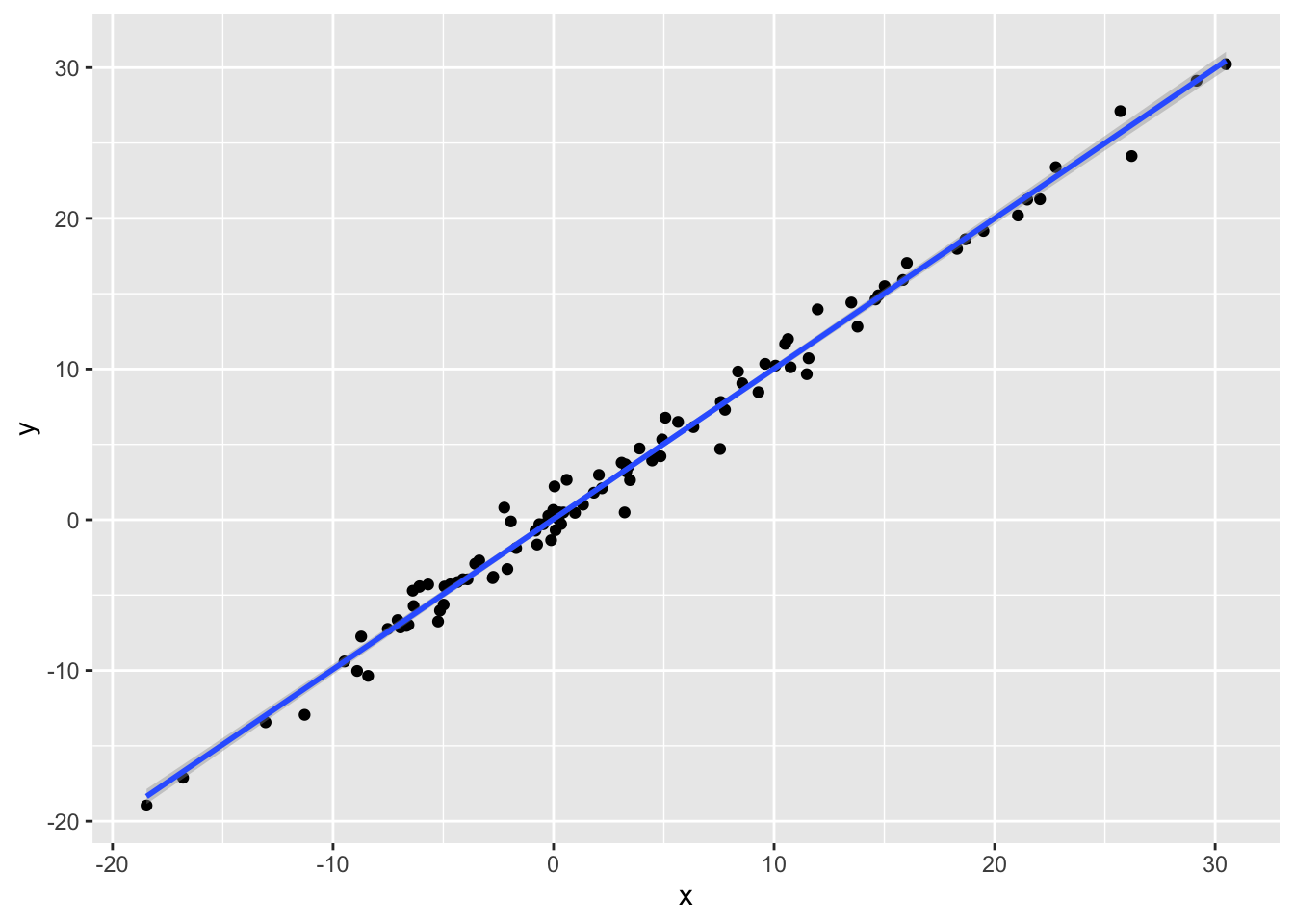
公式保存了创建它的环境
使用到 R 的朋友几乎都用过公式,它在统计建模方面给了我们极大的方便。不过,公式相比于数值、逻辑值这些数据类型,有什么特点吗?
答案是可以通过你应该常用的 str() 函数进行窥探:
str(y ~ x)
#> Class 'formula' language y ~ x
#> ..- attr(*, ".Environment")=<environment: R_GlobalEnv>从属性部分我们可以看到公式保存了创建它的环境。
公式生成匿名函数
利用公式这一特点,tidyverse 系列包有很多函数支持用单侧公式替换函数。如果你仔细阅读过相关文档,例如 ?purrr::map,你应该会看到下面一段话:
If a formula, e.g. ~ .x + 2, it is converted to a function. There are three ways to refer to the arguments:
For a single argument function, use .
For a two argument function, use .x and .y
For more arguments, use ..1, ..2, ..3 etc
This syntax allows you to create very compact anonymous functions.公式的左侧内容对于构造匿名函数没有用,所以这里都是用单侧公式。
这段文档不仅告诉了我们如何通过公式构造匿名函数,还提供了一些快捷方式说明。
下面我们通过一些例子来进行讲解。
公式函数用法
核心是什么
公式函数的优点在于提供了一种构造匿名函数的简洁方式。而核心在于在同一行代码表示如何使用输入构造出输出。
例如,~ .x + 2 代表直接在输入的基础在加 2,其等价于下面这个匿名函数:
function(x) {
return(x + 2)
}你应该瞬间明白了公式函数多么简洁。这里值得注意的是,当匿名函数只有一个参数时,我们用 .x 表示函数的输入参数。如果进行拓展,2 个参数时使用 .x 与 .y,3 个参数时使用 ..1, ..2, ..3 等。
通过下面的例子,我们来学习如何基本掌握它的用法。
基本用法
假设我们要对 df 中的 x 和 y 列进行归一化处理,在不使用 scale() 函数的情况下,我们可能会手写一个函数:
scale2 <- function(x) {
(x - mean(x)) / sd(x)
}把它们逐一应用起来:
df2 <- df
df2$x <- scale2(df$x)
df2$y <- scale2(df$y)
df2 <- as_tibble(df2)这里完全不必要先构造一个函数再应用 2 次,使用公式函数结合 purrr 可以写出更简洁的代码:
df3 <- purrr::map_df(df, ~ (.x - mean(.x)) / sd(.x))我们检查下两种操作是否结果相同:
identical(df2, df3)
#> [1] TRUE当只有一个参数时,我们还可以使用 . 替换 .x 进一步简化编写。
identical(
purrr::map_df(df, ~ (.x - mean(.x)) / sd(.x)),
purrr::map_df(df, ~ (. - mean(.)) / sd(.))
)
#> [1] TRUE在理解了上述操作后多个参数的使用也就不难理解了,接下来我们看一个更加实际的例子。
计算残差
最开始的图形显示了 x 和 y 是一个线性关系,假设我们目前有一个任务:构建回归模型并手动计算残差,绘制结果图。
我们来看看如何操作。
第一步:建模
fit <- lm(y ~ x, data = df)模型构建好后我们提取系数值:
cfs <- coef(fit)
cfs
#> (Intercept) x
#> 0.0502 0.9974第二步:计算残差
得到模型系数后我们就知道了如何计算预测值,将真实值与预测值相减则可以得到残差值。
df <- df %>%
mutate(
rs = map2_dbl(x, y, ~ .y - (cfs[2] * .x + cfs[1]))
)理解上述代码:
x和y指代df$x和df$y,这里使用了dplyr包的mutate()语境,所以可以直接写列名。因此,你也完全可以这样写:
df$rs2 <- map2_dbl(df$x, df$y, ~ .y - (cfs[2] * .x + cfs[1]))
head(df)
#> x y rs rs2
#> 1 -7.07 -6.66 0.3459 0.3459
#> 2 7.77 7.30 -0.5046 -0.5046
#> 3 15.84 15.91 0.0571 0.0571
#> 4 -18.46 -18.96 -0.6008 -0.6008
#> 5 9.29 8.47 -0.8520 -0.8520
#> 6 10.06 10.23 0.1430 0.1430不难想到,下面的操作也是可以的:
map2_dbl(df$x, df$y, ~ ..2 - (cfs[2] * ..1 + cfs[1]))
#> [1] 0.345883 -0.504636 0.057127 -0.600819 -0.851959 0.143036 -0.948411
#> [8] 0.116772 0.303091 -0.112476 -0.245536 -0.712267 -1.167170 0.813802
#> [15] 0.010237 0.791110 -1.294772 0.108104 0.614175 -0.000413 -0.225049
#> [22] -0.831860 2.009516 0.725336 1.768959 0.005129 -0.653571 -1.577144
#> [29] -0.673649 0.164733 1.005290 0.203190 -1.227608 0.618485 -1.729750
#> [36] -0.433464 -0.410139 -2.020380 0.875227 -0.672179 -0.333381 1.330118
#> [43] 0.577208 -0.152906 0.450671 0.336854 1.596818 0.206081 0.455455
#> [50] 0.297438 -0.461502 0.045282 1.572665 -0.939222 0.080372 1.339664
#> [57] -0.228792 -1.110710 -0.865048 -0.457482 -0.867377 -0.231303 -0.452480
#> [64] -0.237672 0.369704 0.633834 1.611351 -0.070168 -0.323312 1.442629
#> [71] 1.667355 -0.005791 -0.379372 -1.842479 1.428111 -0.878738 -1.197193
#> [78] 2.987737 0.204604 -0.078683 -2.774011 -0.141379 0.903081 0.372182
#> [85] 0.897346 1.964775 1.146301 -0.556396 0.662028 -0.266730 -0.576611
#> [92] -2.886256 -0.782301 0.476785 2.117951 0.472815 0.553460 -0.980149
#> [99] 0.150879 -2.060062- 在公式中,
.x指代x,.y指代y。 - 在公式中,我们可以直接使用前面已经定义的变量,这里是
cfs。
第三步:简单绘制结果图
library(ggplot2)
ggplot(df, aes(x, rs)) +
geom_point()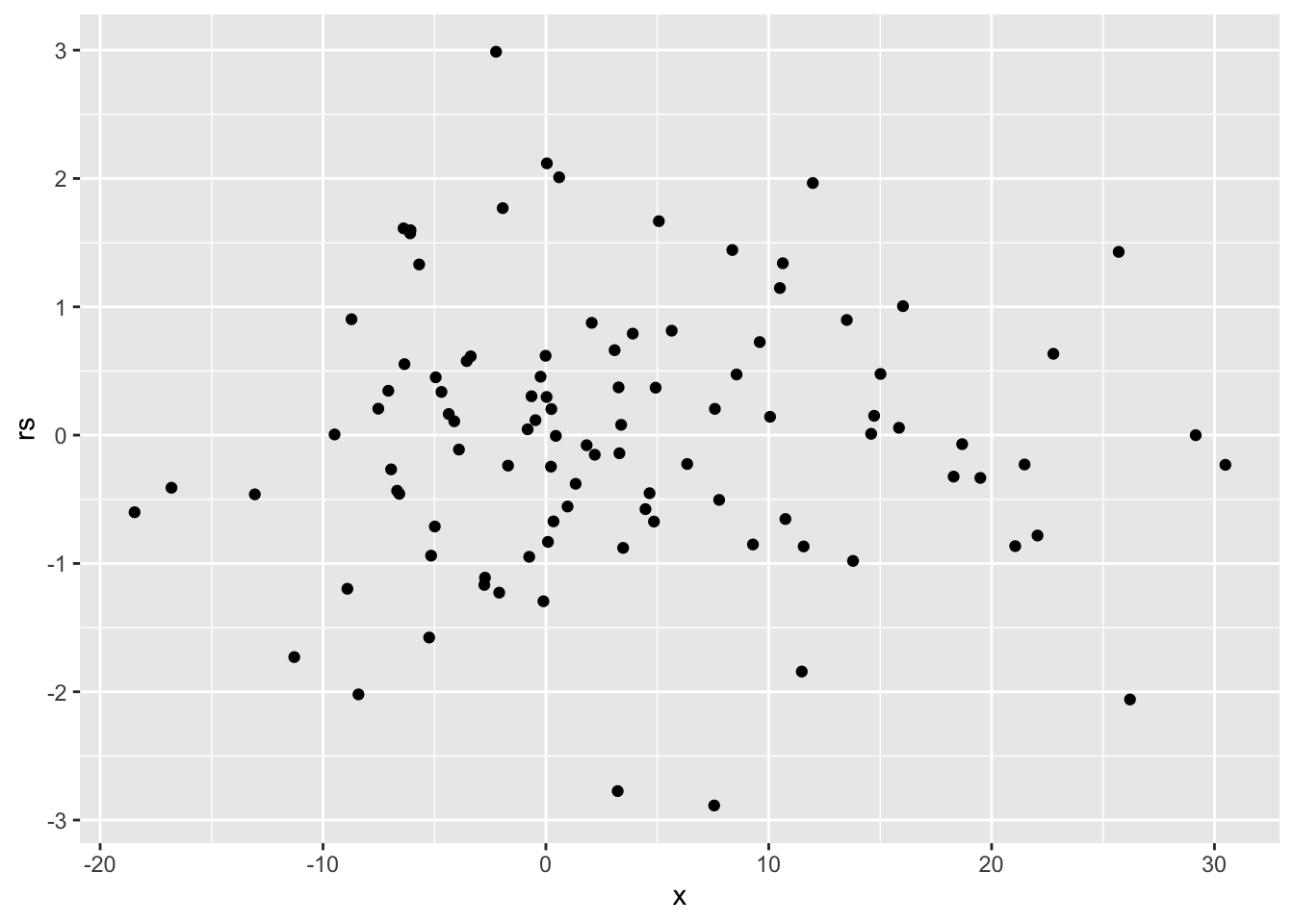 好的模型结果残差分布和我们实际加入的噪声分布应该是差不多的:
好的模型结果残差分布和我们实际加入的噪声分布应该是差不多的:
mean(df$rs)
#> [1] -1.19e-15
sd(df$rs)
#> [1] 1.03提醒
tidyverse 中使用单侧公式简化匿名函数的构造,它并不是必需的技能,直接构造函数在大部分情况下可读性更好,读者千万不要本末倒置。